서포트 벡터 머신(SVM, Support Vector Machine)
1. 어원 (Etymology)
- Support(지지) + Vector(벡터) + Machine(기계): 데이터를 최적의 초평면으로 분리하는 머신러닝 모델을 의미.
- 유래: 1992년 Vladimir Vapnik과 Alexey Chervonenkis가 제안한 이론을 기반으로 개발됨.
2. 정의 (Definition)
**서포트 벡터 머신(SVM, Support Vector Machine)**은 데이터의 클래스(Class)를 분리하는 최적의 초평면(Hyperplane)을 찾는 지도 학습(Supervised Learning) 기반의 머신러닝 알고리즘이다. 주로 **분류(Classification)**와 회귀(Regression) 문제에 사용된다.
🔑 핵심 키워드
상위 개념: 지도학습(Supervised Learning), 분류(Classification), 회귀(Regression), 커널 방법(Kernel Method)
동일 개념: 서포트 벡터 회귀(SVR, Support Vector Regression), 커널 SVM(Kernel SVM), 선형 SVM(Linear SVM)
기술 키워드: 초평면(Hyperplane), 서포트 벡터(Support Vector), 마진(Margin), 커널 트릭(Kernel Trick), 슬랙 변수(Slack Variable)
응용 키워드: 얼굴 인식(Face Recognition), 문서 분류(Text Classification), 질병 진단(Disease Diagnosis), 주가 예측(Stock Prediction)
최신 기술: 딥러닝 기반 SVM, 퀀텀 SVM(Quantum SVM), 강화학습 기반 SVM
문제 해결: 고차원 데이터(High-dimensional Data), 과적합(Overfitting), 계산 비용(Computational Cost)
3. 중요성 (Why?)
SVM은 고차원 데이터에서 강력한 분류 성능을 보이며, 다양한 응용 분야에서 사용됨.
| 관점 | 중요성 |
| 고차원 데이터 처리 | 차원이 높은 데이터에서도 안정적인 분류 성능을 제공 |
| 마진 최적화 | 가장 넓은 마진을 갖는 초평면을 찾아 일반화 성능 향상 |
| 커널 기법 지원 | 비선형 데이터에도 적용 가능 |
| 과적합 방지 | 슬랙 변수 및 정규화 기법을 통해 과적합을 방지 |
| 다양한 응용 가능 | 의료, 금융, 자연어 처리 등 다양한 분야에서 활용 |
📌 결론: SVM은 고차원 데이터와 비선형 문제에서도 강력한 성능을 발휘하는 머신러닝 모델이다.
4. 원리 및 유형 (How & Types)
4.1 원리 (Principle)
1. 초평면(Hyperplane) 찾기
- 데이터 포인트를 분리하여 최적의 초평먄을 설정
- 최평면과 가장 가까운 데이터(Support Vector)간의 거리를 최대화
2. 마진(Margin) 최적화
- 마진을 넓게 확보하여 일반화 성능을 극대화
3. 커널 트릭(Kernel Trick) 적용
- 비선형 데이터를 고차원 공간으로 변환하여 분류 성능 향상
4.2 유형 (Types)
| 유형 | 설명 | 적용 사례 |
| 선형 SVM (Linear SVM) | 데이터가 선형적으로 구분될 때 적용 | 뉴스 기사 분류, 이메일 스팸 필터링 |
| 비선형 SVM (Non-Linear SVM) | 비선형 데이터를 다룰 때 사용 | 이미지 인식, 유전자 분석 |
| 서포트 벡터 회귀(SVR) | 회귀 분석에 적용 | 주가 예측, 수요 예측 |
| 다중 클래스 SVM (Multi-class SVM) | 여러 개의 클래스를 분류할 때 사용 | 손글씨 인식, 자연어 처리 |
📌 결론: 데이터의 분포에 따라 선형/비선형 SVM을 선택하며, 회귀 및 다중 클래스 문제에도 확장 가능함.
5. 아키텍처 및 기술 구성요소 (Architecture & Components)
🔍 SVM의 기본 개념
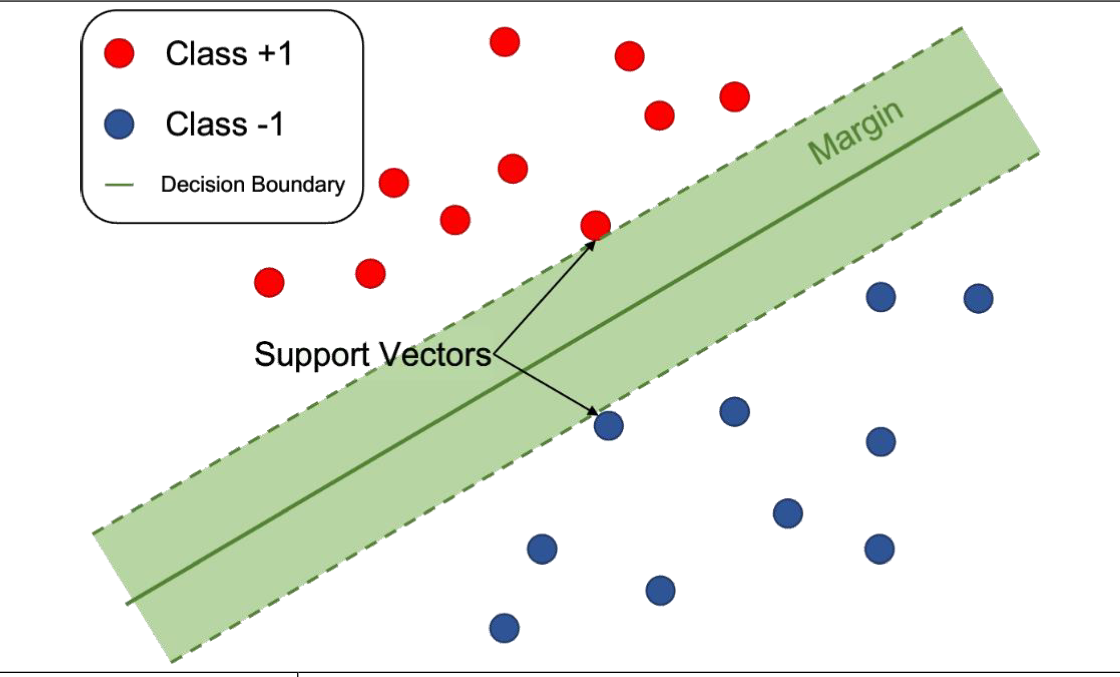
🔧 주요 기술 구성요소
| 구성 요소 | 설명 | 예제 |
| 초평면(Hyperplane) | 데이터를 구분하는 최적의 선(고차원 공간에서는 면) | 2D에서는 선, 3D에서는 평면 |
| 서포트 벡터(Support Vector) | 초평면과 가장 가까운 데이터 포인트 | 마진을 결정하는 핵심 요소 |
| 마진(Margin) | 서포트 벡터와 초평면 간의 거리 | 마진이 클수록 일반화 성능 증가 |
| 커널 트릭(Kernel Trick) | 저차원 데이터를 고차원 공간으로 변환 | RBF, 다항식 커널 |
| 슬랙 변수(Slack Variable) | 일부 오차를 허용하여 유연한 분류 가능 | 과적합 방지 |
📌 결론: SVM의 핵심은 초평면, 서포트 벡터, 마진, 커널 기법이며, 이를 최적화하여 강력한 성능을 발휘함.
6. 비교 분석 (Comparison)
| 비교 항목 | SVM | 로지스틱 회귀 | 랜덤 포레스트 |
| 모델 유형 | 분류/회귀 | 분류 | 분류/회귀 |
| 설명 가능성 | 중간 | 높음 | 낮음 |
| 고차원 데이터 처리 | 강함 | 약함 | 중간 |
| 비선형 분류 | 커널 트릭 사용 | 불가능 | 가능 |
| 계산 비용 | 높음 | 낮음 | 높음 |
📌 결론: SVM은 고차원 및 비선형 데이터에서 강력하지만, 계산 비용이 높아 대규모 데이터에는 적합하지 않을 수 있음.
7. 적용 및 방법론 (Applications & Methodology)
🔹 주요 활용 사례
| 분야 | 적용 사례 |
| 의료 | 질병 진단, 유전자 분석 |
| 금융 | 신용 점수 평가, 부정 거래 탐지 |
| 자연어 처리 | 문서 분류, 감성 분석 |
| 컴퓨터 비전 | 얼굴 인식, 이미지 분류 |
🔹 SVM 구현 (Python)
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# 데이터 로드 및 분할
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# SVM 모델 생성 및 훈련
model = SVC(kernel='rbf', C=1.0, gamma='scale')
model.fit(X_train, y_train)
# 예측 수행
y_pred = model.predict(X_test)
8. 최신 이슈 및 트렌드 (Trends)
- 퀀텀 SVM (Quantum SVM): 양자 컴퓨팅을 이용하여 대규모 데이터 처리 속도 개선.
- 딥러닝과의 융합: CNN-SVM, RNN-SVM 등 하이브리드 모델 활용 증가.
- AutoML 적용: 최적 커널과 하이퍼파라미터 자동 튜닝.
9. 결론 (Conclusion)
| 항목 | 설명 |
| 정의 | 데이터를 최적의 초평면으로 분리하는 머신러닝 알고리즘 |
| 중요성 | 고차원 데이터 처리 및 비선형 분류에서 강력한 성능 |
| 원리 | 초평면 탐색 → 마진 최적화 → 커널 트릭 적용 |
| 비교 분석 | 로지스틱 회귀보다 강력하지만, 계산 비용이 높음 |
| 최신 트렌드 | 퀀텀 SVM, AutoML 적용 증가 |
📌 최종 결론: SVM은 해석 가능성이 높고 비선형 데이터 처리에 강력한 머신러닝 모델로, 최신 기술과 결합하여 더욱 발전하고 있다.
'인공지능' 카테고리의 다른 글
| AGI(Artificial General Intelligence)의 개념과 발전 방향 (0) | 2025.03.11 |
|---|---|
| 마진 유형 (Types of Margin in SVM) (0) | 2025.03.07 |
| 강화 학습(Reinforcement Learning) (0) | 2025.03.05 |
| 지도학습(Supervised Learning) (0) | 2025.03.05 |
| 기계 학습(Machine Learning)과 딥러닝(Deep Learning) 비교 (0) | 2025.03.05 |



